
애플리케이션 코드는 깔끔한데 API는 이상하게 느린 경우가 있습니다. SQL 한 건이 특별히 나쁜 것도 아닌데 응답 시간이 길고, 동시 요청이 늘면 DB 연결도 금방 바빠집니다. 이럴 때 자주 숨어 있는 원인이 N+1 query 문제입니다.
특히 ORM을 쓰면 이 문제가 더 잘 숨습니다. 코드에서는 post.author처럼 자연스러운 속성 접근처럼 보이지만, 실제로는 목록 1번 조회 뒤 관계 데이터 조회가 수십 번, 수백 번 더 나가고 있을 수 있기 때문입니다.
이 글은 아래 질문에 답하기 위해 정리했습니다.
- N+1 query가 정확히 무엇인지
- 왜 ORM 환경에서 특히 자주 생기는지
- 운영에서 어떻게 빨리 찾는지
JOIN, eager loading, batch fetch 중 무엇을 선택해야 하는지
짧게 말하면 N+1 문제는 “쿼리 하나가 느린가”보다 “불필요한 round trip이 구조적으로 폭증하는가”의 문제입니다.
Quick answer
MySQL N+1 query를 빠르게 정리하려면 아래 순서가 가장 실용적입니다.
- 목록 화면이나 API 한 번 호출에 몇 개의 SQL이 나가는지 센다
- 같은 형태의
SELECT ... WHERE id = ?가 반복되는지 본다 - 부모 목록 1건 조회 뒤 관계 조회가 N번 더 붙는 구조인지 확인한다
- 필요한 데이터가 정해져 있다면
JOIN이나 eager loading으로 미리 가져온다 - 관계가 너무 많거나 row 폭증이 걱정되면 batch fetch로 묶어서 읽는다
- 수정 뒤에는 쿼리 개수와 응답 시간을 함께 비교한다
즉, N+1 최적화의 핵심은 SQL 문장 하나를 더 빠르게 만드는 것이 아니라 요청 하나가 DB를 몇 번 왕복하는지 줄이는 것입니다.
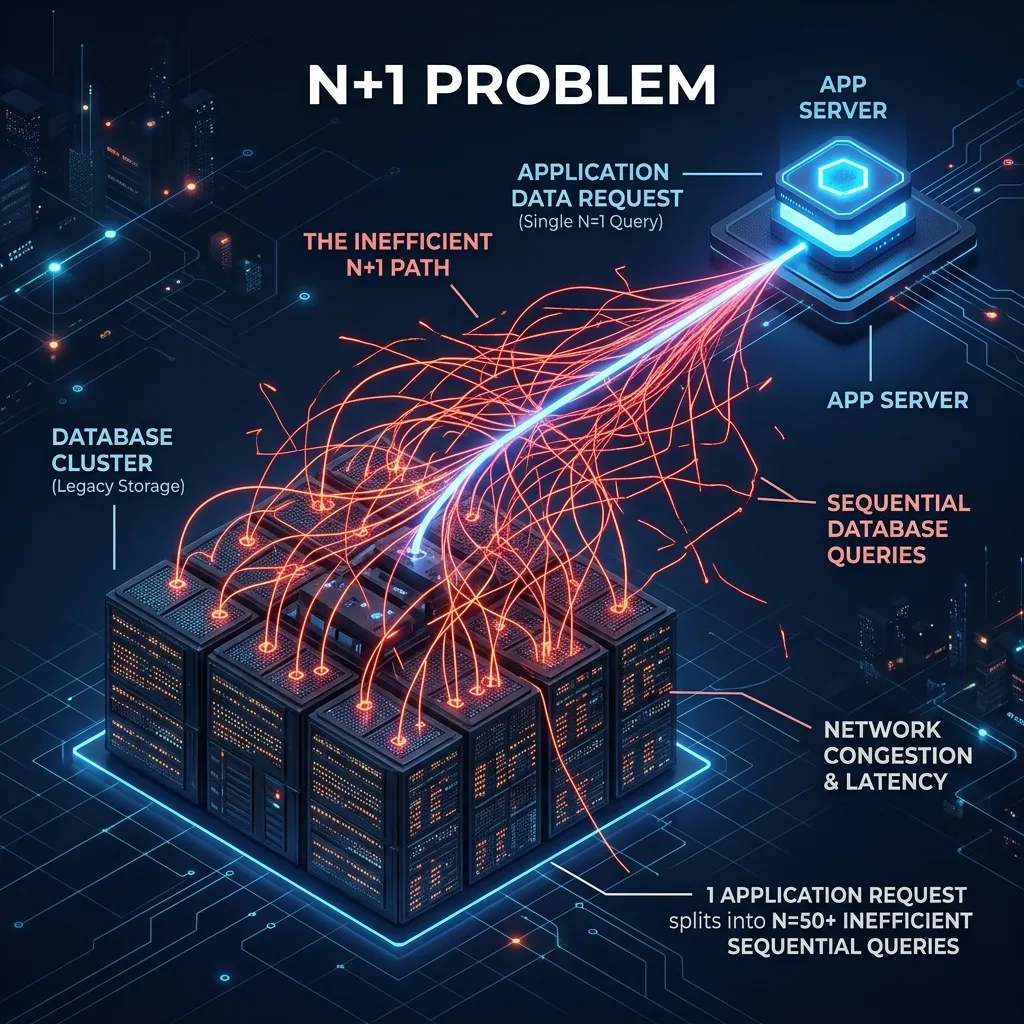
1. N+1 query란 무엇인가
가장 전형적인 예시는 부모 목록을 먼저 읽고, 각 부모 row마다 자식이나 관계 데이터를 하나씩 다시 읽는 경우입니다.
예를 들어 게시글 100개를 읽은 뒤 각 게시글의 작성자 정보를 따로 읽는다고 가정해 보겠습니다.
SELECT id, title, author_id
FROM posts
ORDER BY created_at DESC
LIMIT 100;그다음 애플리케이션이 각 게시글마다 아래 쿼리를 다시 실행한다면:
SELECT id, name
FROM users
WHERE id = ?;결국:
- 게시글 목록 조회 1번
- 작성자 조회 100번
이 되어 총 101개의 쿼리가 나갑니다. 이것이 대표적인 N+1 구조입니다.
이 문제의 핵심은 개별 쿼리 하나가 아주 느릴 필요조차 없다는 점입니다. 5ms짜리 쿼리 100개가 쌓이면, 애플리케이션과 DB는 충분히 체감 가능한 병목을 만들 수 있습니다.
2. 왜 ORM에서 특히 잘 숨는가
ORM이 나쁘다는 뜻은 아닙니다. 오히려 ORM은 생산성을 크게 높여 줍니다. 문제는 ORM이 객체 접근을 너무 자연스럽게 만들어서, 쿼리 수 폭증이 코드에서 잘 보이지 않는다는 데 있습니다.
예를 들어 코드에서는 아래처럼 보일 수 있습니다.
for (const post of posts) {
console.log(post.author.name);
}개발자 입장에서는 단순히 속성 접근처럼 보이지만, ORM 설정이나 lazy loading 방식에 따라 내부에서는:
posts1회 조회- 각
post.author접근마다 추가 조회
가 일어날 수 있습니다.
즉, 코드의 가독성과 실제 SQL 수는 전혀 다른 이야기일 수 있습니다.
그래서 ORM 환경에서는 “코드가 깔끔하니 괜찮겠지”보다 **“이 요청 하나가 실제로 몇 번 질의하는가”**를 확인하는 습관이 더 중요합니다.
3. 왜 성능을 망치는가
N+1 문제는 단순히 쿼리 개수만 많아지는 문제가 아닙니다. 운영에서는 아래 비용이 한꺼번에 커집니다.
- DB round trip 증가
- 네트워크 왕복 증가
- connection 점유 시간 증가
- 애플리케이션 직렬 처리 시간 증가
특히 트래픽이 붙으면 문제가 더 커집니다. 예를 들어 사용자 한 명의 요청에서 100개의 추가 쿼리가 나간다면, 동시 요청 50개만 와도 DB는 짧은 시간에 엄청난 수의 작은 조회를 처리해야 합니다.
즉, N+1은 “개별 쿼리가 조금 비효율적이다”보다 **“시스템 전체가 불필요한 작업을 너무 많이 반복한다”**에 더 가깝습니다.
4. 운영에서 N+1을 빨리 찾는 방법
실무에서는 N+1을 개념보다 증상으로 먼저 만나는 경우가 많습니다. 아래 신호가 보이면 의심해 볼 만합니다.
- 목록 API 하나가 예상보다 SQL을 너무 많이 실행한다
- 같은 형태의
SELECT ... WHERE id = ?가 짧은 시간에 반복된다 - ORM 디버그 로그를 켜면 비슷한 쿼리가 줄줄이 보인다
- SQL 하나하나는 빠른데 전체 응답 시간은 길다
가장 쉬운 출발점은 “요청 한 번에 SQL이 몇 개 나가는지”를 세는 것입니다.
예를 들어:
- 목록 20건 API인데 쿼리가 2~3개면 자연스러울 수 있음
- 목록 20건 API인데 쿼리가 41개, 81개, 121개면 N+1을 강하게 의심
또한 로그에서 아래 패턴이 보이면 거의 정답에 가깝습니다.
SELECT id, title, author_id FROM posts ...;
SELECT id, name FROM users WHERE id = 11;
SELECT id, name FROM users WHERE id = 42;
SELECT id, name FROM users WHERE id = 87;
SELECT id, name FROM users WHERE id = 15;즉, 부모 목록 한 번 뒤에 관계 조회가 하나씩 반복되는 흐름입니다.
5. 가장 먼저 해야 할 질문: 화면이 정말 어떤 데이터를 필요로 하는가
N+1을 줄일 때 흔히 곧바로 JOIN만 떠올리지만, 그 전에 더 중요한 질문이 있습니다.
“이 화면이나 API는 실제로 어떤 데이터 shape를 한 번에 필요로 하는가?”
예를 들어 게시글 목록 화면이 정말 필요한 것은:
- 게시글 제목
- 작성자 이름
- 작성일
정도일 수 있습니다. 그런데 상세 화면에나 필요한:
- 작성자 프로필 전체
- 댓글 전체
- 태그 전체
- 좋아요 집계 전체
를 목록 단계에서 모두 끌고 오려 하면, N+1을 없애다가 오히려 과도한 JOIN이나 과도한 payload를 만들 수도 있습니다.
즉, 해결의 첫걸음은 “무조건 한 번에 다 가져오기”가 아니라 **“이 요청이 필요한 최소 데이터 집합을 먼저 분명히 하는 것”**입니다.
6. 해결 방법 1: JOIN이나 eager loading으로 미리 가져오기
관계가 단순하고 화면에서 꼭 필요한 데이터가 명확하다면 가장 쉬운 해결책은 미리 함께 읽는 것입니다.
예를 들어 게시글 목록에서 작성자 이름이 꼭 필요하다면:
SELECT p.id, p.title, u.name AS author_name
FROM posts p
JOIN users u ON u.id = p.author_id
ORDER BY p.created_at DESC
LIMIT 100;처럼 한 번의 쿼리로 해결할 수 있습니다.
ORM에서도 보통:
- eager loading
- include / preload
- fetch join
같은 방식으로 같은 효과를 낼 수 있습니다.
이 접근이 좋은 경우는 보통 아래와 같습니다.
- one-to-one 또는 many-to-one 관계
- 목록에서 반드시 필요한 관계 데이터
- row 폭증 위험이 크지 않은 관계
즉, “작성자 이름”, “카테고리 이름”처럼 비교적 단순한 관계는 미리 붙이는 편이 자연스럽습니다.
7. 해결 방법 2: batch fetch로 묶어서 읽기
항상 큰 JOIN이 정답은 아닙니다. 관계가 복잡하거나 one-to-many 폭증이 걱정된다면, 두 단계로 나누되 N번 조회 대신 묶어서 조회하는 편이 낫습니다.
예를 들면:
- 게시글 100개를 읽는다
- 그 게시글들의
author_id를 모은다 WHERE id IN (...)으로 작성자를 한 번에 읽는다- 애플리케이션에서 매핑한다
SQL 형태로 보면 이런 느낌입니다.
SELECT id, title, author_id
FROM posts
ORDER BY created_at DESC
LIMIT 100;
SELECT id, name
FROM users
WHERE id IN (11, 42, 87, 15, ...);이 방식의 장점은:
- 쿼리 수를 크게 줄일 수 있고
- 거대한 JOIN보다 제어가 쉬우며
- 관계 데이터 재사용이 편할 수 있다는 점입니다
즉, N+1을 없애는 방법은 “1 쿼리만 허용”이 아니라 **“N번 추가 조회를 소수의 예측 가능한 조회로 바꾸는 것”**입니다.
8. JOIN과 batch fetch 중 무엇을 고를까
실무에서는 이 판단이 중요합니다. 대략 아래 기준으로 생각하면 편합니다.
JOIN이 잘 맞는 경우:
- 관계가 단순하다
- 목록에서 바로 필요한 필드가 적다
- one-to-many row 폭증이 크지 않다
batch fetch가 잘 맞는 경우:
- 관계가 여러 단계로 이어진다
- 한 번에 거대한 JOIN을 만들면 row가 너무 불어난다
- 애플리케이션에서 조합하는 편이 더 단순하다
중요한 것은 “무조건 JOIN”도 아니고 “무조건 ORM include”도 아니라는 점입니다. 핵심은 쿼리 수와 쿼리 복잡도 사이의 균형입니다.
즉:
- 지금은 쿼리 수가 너무 많은가
- 아니면 한 번의 JOIN이 너무 큰 row 폭증을 만들고 있는가
를 같이 봐야 합니다.
9. 어디서 특히 자주 터지는가
N+1은 아래 같은 화면이나 API에서 자주 생깁니다.
- 목록 화면
- 댓글, 작성자, 태그처럼 관계가 많은 페이지
- 관리자 페이지 통계/집계 화면
- serializer나 DTO 변환 과정에서 관계 접근이 반복되는 코드
특히 “부모 목록을 읽고 각 row마다 관계를 따라간다”는 구조가 보이면 거의 항상 의심해 볼 가치가 있습니다.
예를 들어:
- 게시글 목록에서 작성자/댓글 수/태그를 각각 다시 읽는 경우
- 주문 목록에서 고객, 배송지, 결제 상태를 각 row마다 다시 읽는 경우
- 관리자 표에서 행마다 집계 쿼리를 다시 날리는 경우
이런 패턴은 초기 데이터가 작을 때는 잘 안 보이지만, 운영 데이터가 쌓이면 갑자기 급격히 느려질 수 있습니다.
10. 수정 뒤에 무엇을 비교해야 하는가
N+1을 수정한 뒤 “느낌상 빨라진 것 같다”로 끝내면 다음 화면에서 같은 문제가 반복됩니다. 최소한 아래는 같이 비교하는 편이 좋습니다.
- 요청 1회당 SQL 개수
- 응답 시간
- DB connection 사용량
- 같은 쿼리 반복 횟수
예를 들어 개선 전에는:
- SQL 101개
- 응답 1.2초
였는데 개선 후:
- SQL 3개
- 응답 220ms
가 됐다면, 단순히 쿼리 수만 줄어든 것이 아니라 DB 왕복과 애플리케이션 대기 시간이 함께 줄어든 것입니다.
즉, N+1 개선은 “쿼리 튜닝”이라기보다 요청 단위 아키텍처를 더 효율적으로 만드는 작업에 가깝습니다.
자주 하는 오해
1. ORM이 알아서 최적화해 줄 것이다
일부 프레임워크는 도움을 주지만, 관계 접근 패턴까지 항상 자동 최적화하지는 않습니다.
2. 각 쿼리가 빠르면 괜찮다
빠른 쿼리 100개는 충분히 큰 병목이 될 수 있습니다.
3. JOIN만 쓰면 항상 해결된다
one-to-many 관계가 많으면 거대한 JOIN이 오히려 row 폭증과 중복 처리 비용을 키울 수 있습니다.
4. 작은 서비스니까 나중에 봐도 된다
초기에는 숨어 있다가 데이터와 트래픽이 늘 때 갑자기 운영 문제로 바뀌기 쉽습니다.
FAQ
Q. N+1은 어떻게 가장 빨리 발견하나요?
요청 단위로 쿼리 수를 세고, ORM 디버그 로그나 SQL 로그에서 비슷한 SELECT ... WHERE id = ? 패턴이 반복되는지 보는 것이 가장 빠릅니다.
Q. eager loading을 쓰면 무조건 괜찮아지나요?
아닙니다. 단순 관계에는 매우 유용하지만, 관계가 많고 row 폭증이 큰 경우에는 batch fetch나 다른 조합이 더 나을 수 있습니다.
Q. EXPLAIN도 같이 봐야 하나요?
네. N+1은 쿼리 수 문제지만, 묶어서 가져온 새 쿼리가 또 비효율적일 수 있으므로 실제 계획도 함께 보는 편이 안전합니다.
Read Next
- 새로 만든 묶음 쿼리가 실제로 어떤 계획으로 도는지 보려면 MySQL EXPLAIN 가이드를 같이 보면 좋습니다.
- 전체 점검 흐름은 MySQL query optimization checklist와 자연스럽게 이어집니다.
- 읽는 양과 조인 비용을 더 넓게 보려면 MySQL slow query 가이드도 도움이 됩니다.
먼저 읽어볼 가이드
검색 유입이 많은 핵심 글부터 이어서 보세요.
- 미들웨어 트러블슈팅 가이드: Redis, RabbitMQ, Kafka 중 어디부터 볼까 Redis, RabbitMQ, Kafka가 함께 있는 시스템에서 지금 보이는 장애가 어느 계층에 더 가까운지, 첫 10분 안에 무엇을 확인하고 어떤 글로 들어가야 하는지 정리한 실전 허브 가이드입니다.
- Kubernetes CrashLoopBackOff: 먼저 볼 것들 startup failure, probe, config, resource limit 관점에서 CrashLoopBackOff를 어떻게 나눠서 봐야 하는지 정리한 가이드입니다.
- Astro 기술 블로그 SEO 체크리스트: 트래픽 기다리기 전에 먼저 고칠 것 Astro 기술 블로그를 위한 실전 SEO 체크리스트입니다. 배포 호스트 확인, robots.txt, sitemap, canonical, hreflang, 구조화 데이터, 페이지별 메타데이터, noindex 판단, 검증 명령까지 우선순위대로 정리합니다.
- 다국어 블로그 canonical과 hreflang 설정 가이드: 무엇을 확인하고 어디서 깨질까 다국어 블로그에서 canonical과 hreflang을 어떻게 설정해야 하는지 실전 기준으로 정리합니다. self-canonical, 상호 연결되는 hreflang 묶음, x-default, 카테고리 페이지, 최종 렌더 HTML 점검, 한 언어 버전이 다른 언어 버전을 눌러버리는 실수까지 다룹니다.
- OpenAI Codex CLI 설치 가이드: 설치, 인증, 첫 작업까지 OpenAI Codex CLI를 실전 기준으로 설치하는 방법을 정리했다. 설치, 로그인, 첫 실행, Windows 주의점, 첫 작업을 어떻게 시작하면 좋은지까지 다룬다.